Redes convolucionais são o atual estado da arte em tarefas de classificação e reidentificação de imagens. Treinadas de ponta a ponta através de backpropagation, suas diferentes camadas são capazes de extrair uma hierarquia de características importantes de imagens e resolver problemas complexos da indústria que de outra forma teriam soluções subpar e ineficientes.
Para tanto, a profundidade é fator crucial em termos de performance, fazendo com que redes convolucionais modernas cheguem a centenas de camadas. Porém, expandir a capacidade de um modelo não é tarefa tão fácil quanto simplesmente agrupar mais camadas ao todo em uma arquitetura existente — problemas como gradientes explodindo/desaparecendo exigem consideração no projeto de arquiteturas mais profundas. Por isso, o desenvolvimento das resnets em 2015, época na qual modelos muito profundos costumavam não ter mais que vinte camadas, foi um dos mais influentes desdobramentos na campo da visão computacional, guiando até mesmo as arquiteturas mais queridas da indústria hoje.
O presente post tem o objetivo de oferecer uma introdução tanto da intuição quanto da implementação dos blocos básicos que compõe uma resnet. Ao final, você deverá ser capaz de compreender fundamentos importantes dessas redes e implementar os blocos básicos que as compõe. Para isso, pressupõe-se conhecimento básico de redes neurais e camadas de convolução.
Motivação
Profundidade é fator crucial para a capacidade de uma rede neural, pois redes neurais mais profundas possuem maior quantidade de parâmetros, e é a interação entre esses parâmetros que as possibilita modelar funções complexas e atingir resultados superiores nas tarefas que desempenham. Dito isso, seria de se esperar que uma arquitetura mais profunda produza resultados se não melhores, no mínimo tão bons quanto os obtidos através de uma mais rasa; porém, nem sempre é o que acontece.
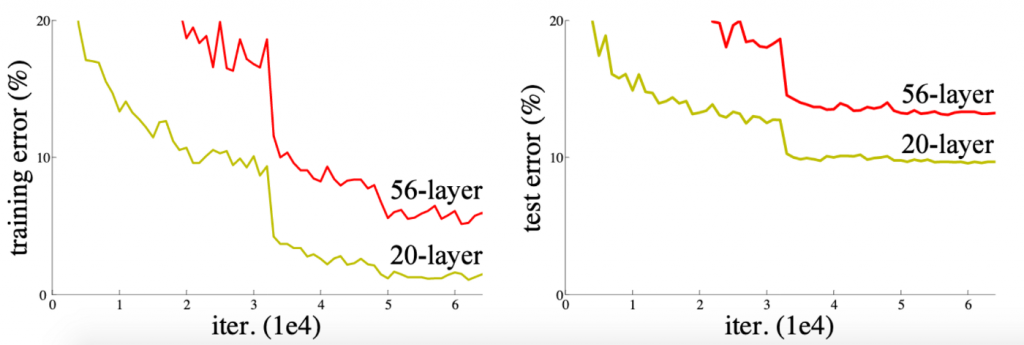
Figura 1: Uma rede com 56 camadas demonstra resultados piores que uma rede mais limitada com apenas 26 camadas.
Chegamos à motivação das resnets: a partir de uma rede mais rasa, deve ser possível projetar uma rede mais profunda que atinja resultados, pelo menos, tão bons quanto o da rede original. Para isso, foi projetado o bloco básico constituinte da resnet. Já o bloco residual ou resblock veremos a seguir.
O bloco residual e como ele funciona
Em termos simples, uma resnet possui dois tipos de blocos residuais. O primeiro, mais simples, é composto por duas ou mais convoluções, cuja saída final possui tamanho compatível com a entrada. Após passar pelas camadas do bloco, o resultado é simplesmente somado, elemento a elemento e canal a canal, à entrada do bloco. Podemos observar o processo a seguir:
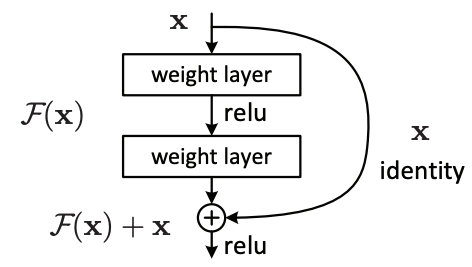
Explicando de forma mais clara, suponhamos que a entrada x do bloco seja uma imagem colorida de 128 x 128 x 3 (largura x comprimento x canais de cor). Além disso, conferimos que a saída após a segunda camada também tenha as dimensões da entrada 128 x 128 x 3. Podemos, então, somá-lo à entrada x e obteremos a saída do bloco residual.

O bloco acima é composto por duas camadas convolucionais. Note a presença de padding na primeira camada para manter o output com as mesmas dimensões, altura e largura, da entrada. Aqui, fazemos uma ressalva: embora o bloco esteja sendo apresentado no contexto de redes convolucionais, o mesmo princípio também funciona para camadas lineares.
Contudo, ao longo de uma rede convolucional, espera-se que a entrada tenha seu tamanho reduzido. Ao passo que o número de canais aumenta, obtemos esse comportamento com o segundo tipo de bloco residual, uma pequena mudança no bloco acima, colocando uma convolução no caminho da identidade que reduza seu tamanho a dimensões apropriadas e aumente o número de canais, tornando a compatível para a soma com F(x).

Agora que possuímos todas as peças-chave, podemos olhar a arquitetura de uma das resnets mais utilizadas, a Resnet34.
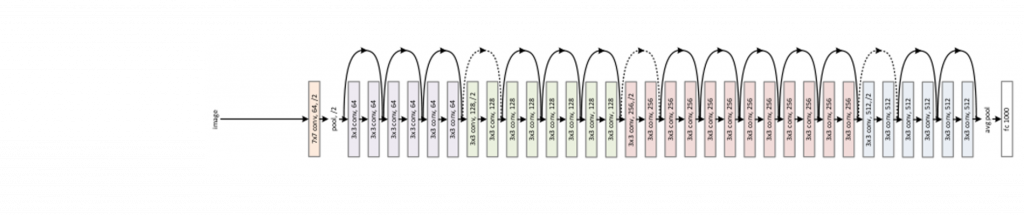
Resnet 34: as linhas sólidas representam o bloco identidade, com a saída mais a dimensão da entrada, enquanto as linhas pontilhadas representam a entrada através de blocos com downsample.
Como podemos observar, a rede nada mais é do que a junção dos dois blocos básicos seguidos, alternando de acordo com a presença ou não de downsample da entrada (linhas contínuas são o primeiro bloco, enquanto linhas pontilhadas são o segundo bloco). Ao final, temos um average pool e a camada de classificação.
Por fim, notamos por que uma resnet mais profunda deve, em teoria, ter um resultado no mínimo tão bom quanto uma menos profunda. Para tanto, imagine o que ocorreria se a rede “aprendesse” os parâmetros das primeiras quatro convoluções como zero: o resultado de cada um desses blocos residuais seria simplesmente a entrada, seria como se eles não existissem e a rede seria equivalente a uma rede menos profunda. É esse o fundamento de uma rede residual que ao somar a entrada em cada bloco torna a rede, embora mais profunda, não é mais complexa que uma VGG básica em respeito ao treinamento.
Além disso, quando olhamos para as linhas contínuas e pontilhadas sobre a rede, notamos uma espécie de rodovia (um caminho facilitado) para os gradientes fluírem durante o passo de backpropagation.
DenseNets
Após compreendermos o bloco residual, acabamos entendendo também o funcionamento básico do bloco denso, constituinte-base das DenseNets, outra arquitetura extremamente poderosa e utilizada na indústria.
Esse bloco simplesmente é o bloco residual com a seguinte alteração: em vez de somar os canais ao final do bloco, o resultado de F(x) é concatenado à entrada x aumentado o número de canais.
Embora a implementação de uma densenet possa ser ligeiramente mais complexa, envolvendo camadas de pooling entre blocos densos para evitar que o número de canais cresça demasiado, convidamos você a ler o artigo original dessa arquitetura aqui.
Este artigo foi originalmente publicado no Medium do Dalisson Figueiredo, republicado na Minds Digital com autorização do autor.

A seguir, você vai aprender sobre: